This article is for beginners as well as intermediate level machine learning enthusiasts.
1. Entropy
Entropy - In general term, entropy measures randomness. When dealing with data, Entropy measures randomness in data/information being processed. If a data has high order or randomness, it becomes difficult to derive any pattern, conclusion or predict something out of it. Hence, we say such dataset has high entropy. A complete random outcome will have high order of entropy.
In simple term, Entropy measures the impurity or uncertainty present in the data.
Below, is the given mathematical formula for calculating Entropy for a dataset.

We will disucss about the use of Entropy in below sections.
2. Information Gain
Information Gain
How much information a particular variable or feature contributes to the model. Information gain basically tells the importance of a particular variable or feature toward the target variable or final result.

3. Example with Decision Tree
Example with Decision Tree
Both Entropy and Information gain are very important in determining the performance of a model. Here we will discuss how Entropy and Information Gain is useful in evaluating the model.
Use case
Let us take, we need to forecast whether match will be played or not based on the weather condition. In the below given table

There are "Outlook", "Humidity" and "Wind" as independent variables and "Play" is dependent or target variable.
Below is the example of Decision Tree for the given example. In Decision Tree, which is inverted tree where each branch denotes a decision. Root node is topmost node in Decision Tree.
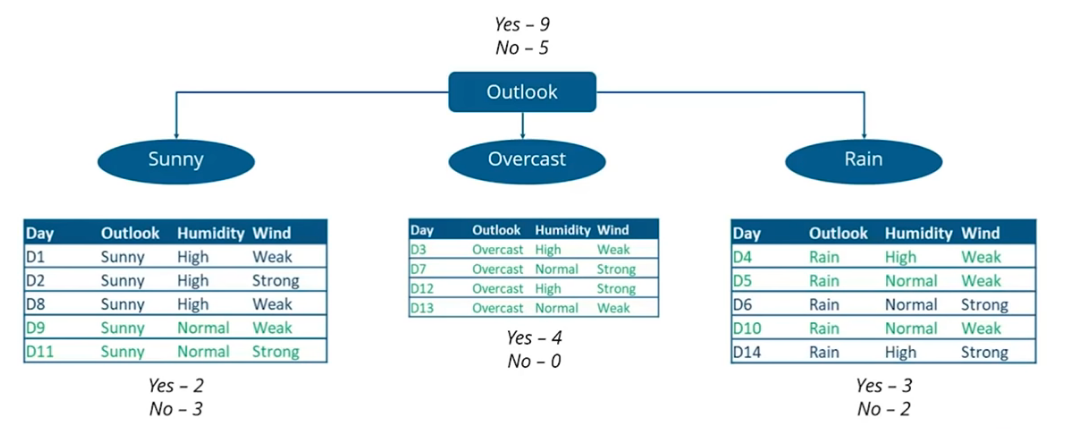
Important point here is, how we will determine, which independent variable we must choose for the root node. A little focussed thinking will tell, the indendent which is very important or contributing most to the target variable or final result must be root node. Now how we can determine which variable is highest contributing toward final result? Answer is: through Information Gain.
In given example, "Outlook" node is choosen as root node, which gives 3 values or possibilities viz. "Sunny", "Overcast" and "Rain". When it is "Overcast", with complete certainity we can say, that answer will be "Yes". In other cases of "Sunny" and "Rain" Yes is with probability: 2/5 and 3/5 respectively as shown in above Decision Tree.
4. Evaluation of Dependent Variable
Let us calculate Entropy first. As there are 9 instances of "Yes" and 5 instances of "No". Hence, Entropy or uncertainity of the data present in sample is 0.940

Let us say, we select root node as all the possible variables "Outlook", "Windy", "Humidity" and "Temperature". For selecting which variable will be best fitted for root node can be obtained by comparing their Information Gain
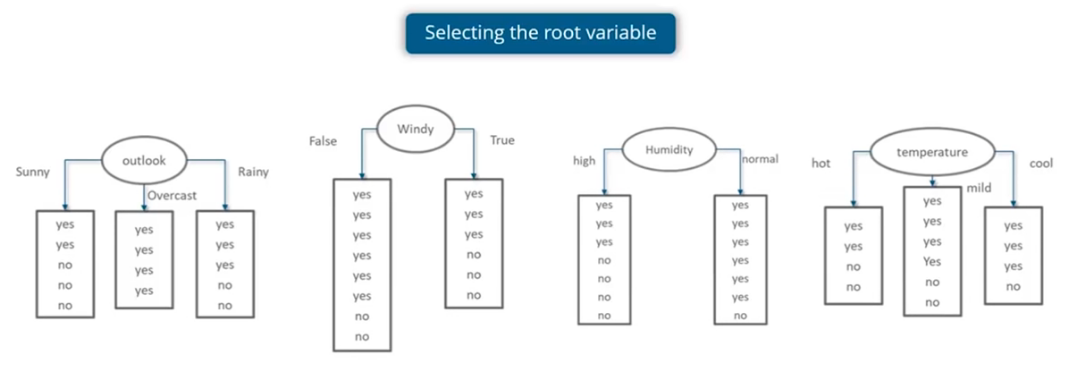
Below are calcuation of Information Gain for 4 Variables: "Windy", "Outlook", "Humidity" and "Temperature".
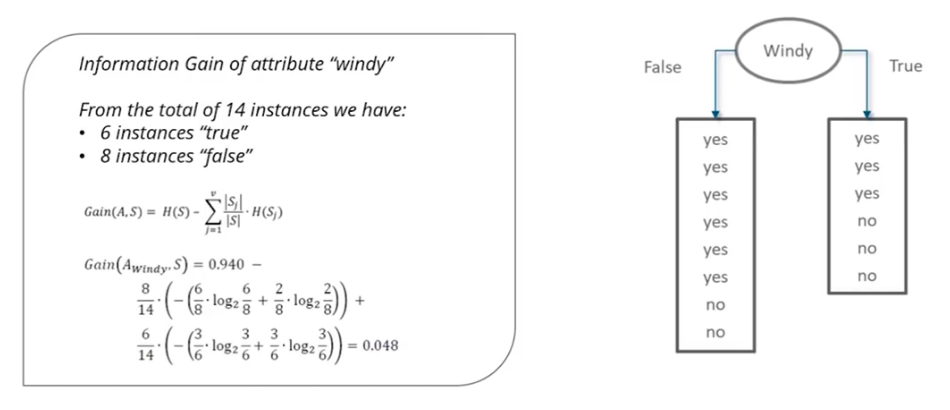
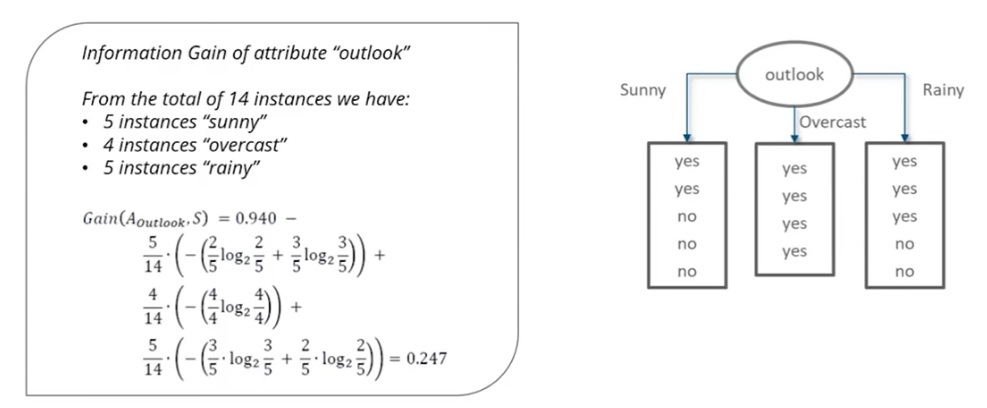

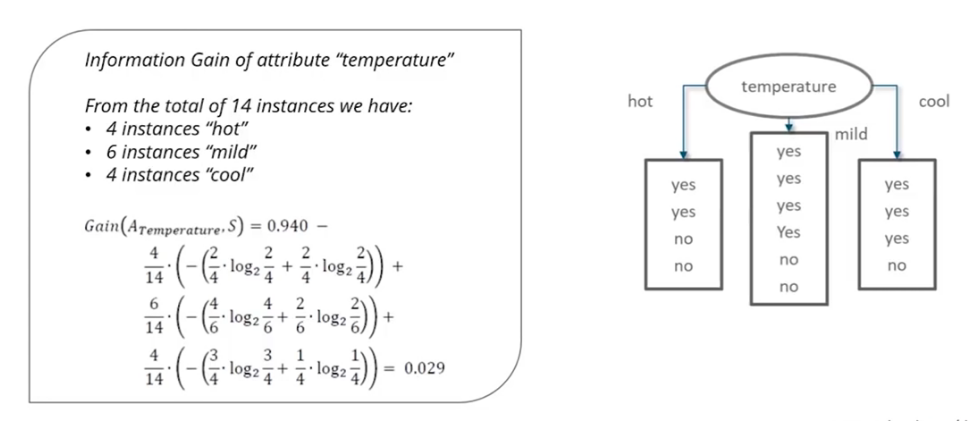
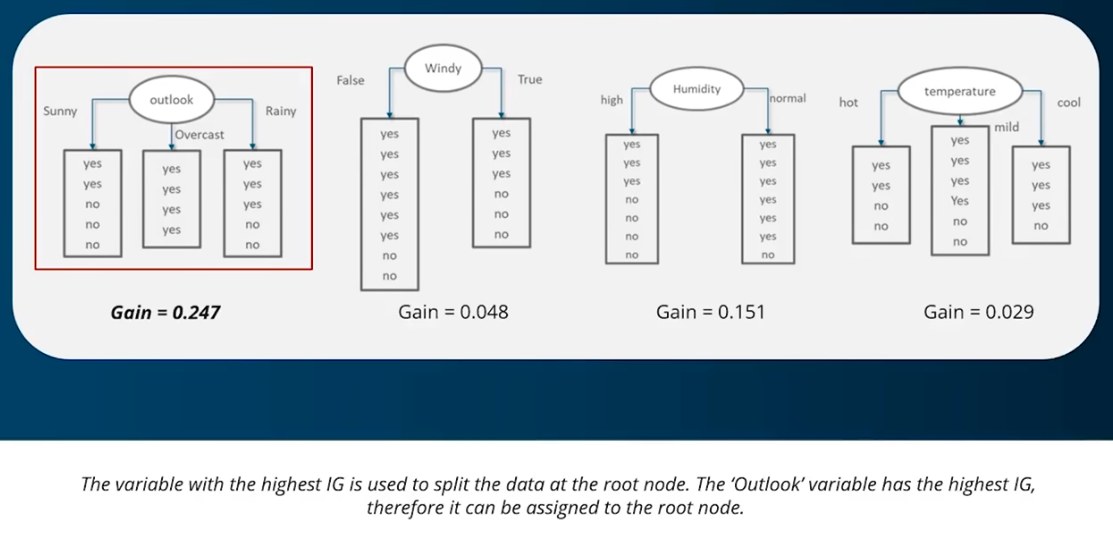
Based on the comparison of Information gains of above 4 cases, highest information gain is obtained when root node is "Outlook". Hence, root node in Decision Tree must be choosen as "outlook".
Thank you for reading it all along. Hope you liked this article!!
About the author
